Introduction
The web as initially conceived was designed primarily to link documents, images, and files without capturing information on the meaning of the relationships. The human user was required to infer meaning from the context of the linked information. This ambiguity severely limits the potential for the data to be leveraged as part of automated machine processes. Several technologies and standards are emerging which aim to address these and other problems by providing a means to relate data stored in different formats using potentially different terminology. Their goal is to provide meaning to data not just structure; semantics in addition to syntax. The implementation of these technologies on the Internet is referred to as the Semantic Web.
The general concept behind the semantic web is the addition of meaning to the data exposed on the web. Today, most websites are formatted such that the data and presentation are one and the same. This relies on an individual’s ability to infer the meaning of the data from its surrounding context on the page. Unfortunately, this makes it very difficult for programs to extract the meaning. What is needed is a means to access data that is geared towards machine consumption and exploitation. The semantic web technologies approach this problem by enabling the construction of a web of machine interpretable data with the capability to include meaning. This is largely achieved through the use of data standards that formalize how data in the form of statements about entities are constructed.
Several key assumptions that are intuitive to most users of the Internet were designed into the Semantic Web. The first of these assumptions is known as the AAA slogan, or “Anyone can Say Anything about Any Topic”. It means that statements about a subject can be made from multiple sources and that these statements may in some cases even conflict. The second is what is known as the Open World Assumption. It means that additional information may be learned in the future and therefore conclusions cannot be made under the premise that all information is known. The last assumption deals with the fact that the same entity may be referred to in different ways by different data sources. For example, a specific data source may include statements about an individual using their Social Security Number (SSN) for identification while a second system may make statements about the same individual using a driver’s license ID, and a third using a passport number. All three sets of statements refer to the same individual and the ability to relate all of the statements may yield additional information. The ability to associate data from multiple sources in order to help answer questions, or draw additional conclusions is the basis of the Semantic Web’s notions of linked data.
The statements about data in the semantic web can be represented in the form of a graph with each statement representing two nodes and an edge. Linking data from one source to another is equivalent to adding links between two separate graphs of data. The Semantic Web includes standards that permit the definition of vocabularies that can be utilized to describe data from multiple sources in the same way. Building upon this, are standards that allow for the construction of information models. They enable class hierarchies to be defined with properties describing the entities they represent. Through the inclusion of data into these models inferences about the data that may not have existed previously can potentially be developed.
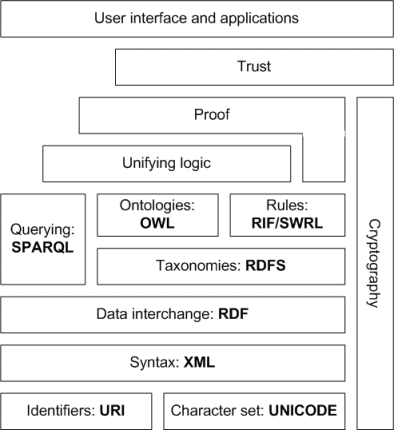
The Semantic Web Stack
The technologies used in the semantic web build upon those used in the document-based web such as unique naming and the Unicode character set. The technologies of the semantic web are often represented in a layered manner in that the higher level technologies build upon the base technologies. This arrangement is often referred to as the Semantic Web Stack or the Semantic Layer Cake and is depicted in below.

Source: Wikipedia semantic-web-stack
It is my intent to discuss the Resource Description Framework (RDF), RDF Schema (RDFS), and the Web Ontology Language (OWL) portions of the Semantic Web Stack in future parts of this blog post series. In addition, I hope to include an example of how these technologies can be used to model a domain and draw inferences.
References
- Hebeler, John, Matthew Fisher, Ryan Blace, and Andrew Perez-Lopez. Semantic Web Programming. Wiley, 2009.
- Allemang, Dean, and James Hendler. Semantic web for the working ontologist modeling in RDF, RDFS and OWL. Amsterdam: Morgan Kaufmann/Elsevier, 2008.

{kind=link}
1 comment:
I think it's pretty cool how when browsing websites on my iphone, sarfari automatically makes phone numbers on websites clickable to easily make a call. I'd imagine detecting phone numbers on websites would be much easier if it included some meta information: 417-343-9090. The firefox skype plugin does the same thing.
Post a Comment