In this fourth part of the introduction to Semantic Web technologies blog series, the OWL (Web Ontology Language) is discussed along with its profiles.
A quick note on tools: So far the discussion has focused on the languages that are used in the Semantic Web and have not mentioned any of the tools that can be used to aid in the development of models. The following discussion of OWL includes references to many additional properties and classes. While it is possible to work with these languages in a text editor having a graphical toolset make the job much easier. Fortunately, there exist excellent commercial and open source packages that fill this need. The two packages that I have used are the open source Protégé 4.0 and the commercially supported TopBraid Composer from TopQuadrant. Both tools are implemented in Java and are therefore cross platform. TopBraid Composer utilizes the Eclipse platform and includes both trials versions and free version. Both include integrated reasoner support. Links to these packages can be found in the Resources and References section at the end of this post.
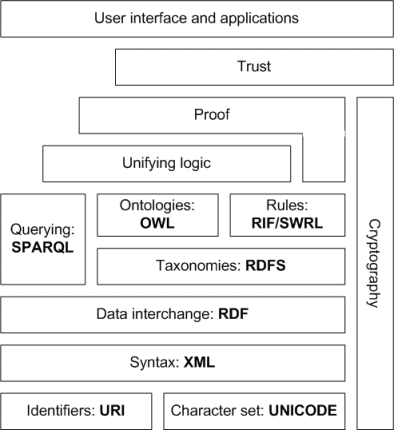
Web Ontology Language
The Web Ontology Language builds on the constructs of RDF and RDFS. Like RDFS, OWL is defined using triples and is valid RDF. The goal of OWL is to add to the expressivity of RDFS. This is accomplished using a set of additional defined classes and properties. Using OWL domain models can be created that are much more expressive than those created with RDFS. With the power of additional expressiveness comes the potential for additional complexity. For example, using OWL it is very easy to define an ontology that includes contradictions or classes that are unsatisfiable (i.e., cannot possibly include any members).
OWL 2 is the latest version of the OWL language. It became a W3C recommendation during the fall of 2009. OWL 2 maintains compatibility with OWL 1 as valid OWL 1 ontologies are also valid in OWL 2. The latest version adds new constructs to add to the expressiveness of the language. These include complex data types, property chains, and multi-property keys for classes to name a few. Everything in this discussion will be valid in OWL 2.
As mentioned above, OWL defines several standard classes and properties to aid in the expressivity of models. One of the first things to note regarding OWL, is that it defines its own class to indicate that a resource is a class instead of an individual. The class
owl:Class is used in OWL instead of the version defined in RDFS,
rdfs:Class. Additionally, OWL defines several new sub classes of the RDF property class
rdf:Property. These include.
owl:ObjectProperty,
owl:DatatypeProperty,
owl:AnnotationProperty, and
owl:OntologyProperty.
The first three new property type classes represent concepts that have been previously discussed. OWL, is essentially adding classes to group them. For example, any property that is defined as being a sub property of
owl:ObjectProperty cannot have a primitive as the object of a triple. The annotation property includes several of the non-semantic RDFS properties such as
rdfs:label and
rdfs:comment. It also includes a sub property to specify version information,
owl:versionInfo. Sub-properties of the
owl:OntologyProperty allow for the specification of version compatibility with the ontology using
owl:priorVersion,
owl:compatibleWith and
owl:incompatibleWith. Likely the most significant sub-property of
owl:OntologyProperty is
owl:imports, as it is through this property that one ontology can include the assertions of another. This plays an important role in the re-use and extension of ontologies.
One of the new classes,
owl:Thing is defined as being the base class from which all other classes are sub classed. Therefore,
owl:Thing is the most generic class in OWL, all classes are sub classes of it, and all individuals are inferred as the type. At the opposite end of the spectrum, OWL defines
owl:Nothing, as the most specific class which cannot have any members. All OWL classes can thus be thought of as being between
owl:Thing and
owl:Nothing. OWL includes a similar concept for properties by defining a property that is the most generic and another which is the most specific. These are referred to as top and bottom properties respectively and OWL includes a set of these properties for both object and data type properties (e.g.,
owl:topObjectProperty,
owl:bottomObjectProperty etc.).
OWL includes a wealth of property classes which can be used in ontologies to model a domain. A complete discussion of the individual properties and the inferences that can be drawn from their use is beyond the scope of this post, however the following table provides a sampling of some of the property classes available in OWL. The Resources and Reference section at the end of this post contains links to information on the use and of these properties.
| OWL Property | Description |
owl:inverseOf |
If P is an inverse property of Q, then if A Q B is asserted, B
PA can be inferred and vice versa |
owl:FunctionalProperty |
If P is a functional property, then if A P B there can be only
a single value of B for a given A |
owl:InverseFunctionalProperty |
If P is an inverse functional property, then if A P B there
can be only a single value of A for a given B |
olw:hasKey |
If A owl:hasKey (X,
Y, Z) then there can be only one value of A for the unique
combination of X, Y, and Z |
owl:ReflexiveProperty |
If P is a reflexive property, then A P A holds for all As |
owl:IrreflexiveProperty |
If P is an irreflexive property, then A P A holds for no As |
owl:SymmetricProperty |
If P is a symmetric property, then If A P B is asserted, then
B P A can be inferred and vice versa |
owl:AsymmetricProperty |
If P is an asymmetric property, then if A P B is asserted, B P
A is a contradiction |
owl:TransitiveProperty |
If P is a transitive property, then if A P B and B P C are
asserted then A P C can be inferred
|
OWL significantly increases the level or expressivity possible in ontologies through the use of property restrictions. Property restrictions allow the ontology designer to place conditions on property relationships that define a class. Restrictions are defined using the
owl:Restriction class and the
owl:onProperty property class. There are two different types of restrictions in OWL, value and cardinality. Value restrictions limit the individuals that can be members of the class while cardinality restrictions limit the number of a specific property that can be defined for a class. Value restriction properties include
owl:allValuesFrom,
owl:someValuesFrom, and
owl:hasValue. In the example below, a chemical compound class is defined as the sub class of an anonymous class that has a molecular formula property which must be a string. OWL specifies that restriction classes must be anonymous.
ChemicalCompound rdf:type owl:class;
rdfs:subClassOf[
rdf:type owl:Restriction;
owl:onProperty molecularFormula;
owl:allValuesFrom xsd:string
].
Cardinality restrictions include
owl:cardinality,
owl:minCardinality, and
owl:maxCardinality. They are specified in the same manner as value restrictions except that the cardinality property restriction includes an integer defining the cardinality limit.
During the discussion of RDFS, it was noted that class membership for an individual entity could either be asserted or inferred. Rules such as the type propagation rule are used in conjunction with the
rdfs:subClassOf property to infer class membership based on their use. OWL includes the ability to infer class membership through the use of restrictions and class equivalency. In the previous example the restriction was used in a sub class relationship. This specifies that all members of the class must adhere to the restriction. OWL provides a property
owl:equivalentClass that allows for the definition that two classes are the same. Used with a restriction, it asserts the additional statement that the restriction is sufficient to define membership in the class (i.e., if a class meets the restriction but is not asserted to be a member of the class, it can be inferred to be a member). This is a powerful concept used often in ontologies to categorize individual entities without the need to have them be declared to be members of the class. It enables new classes to be defined independently of the data and applied for analysis. The Protégé ontology editor refers to classes that have an equivalent class assertion as “Defined” classes and one that do not are referred to as “Primitive” classes.
Defining classes using equivalence and restrictions is not the only use of the
owl:equivalentClass property. It also plays an important role in data integration. In part one of this blog post series, it was mentioned that one of the core problems that the Semantic Web aims to address is the ability to apply consistent concepts across data repositories on the Internet. Currently, data exposed by systems will often use different data formats to represent their data. If the data was exposed using an OWL ontology, the equivalency properties within OWL could be used to align the data from both systems even though they use different ontologies. For example, two systems dealing with consumers of medical services expose data using different ontologies. System 1 refers to the concept of a consumer as a “patient”, while system 2 refers to the same concept as a “client”. If the two concepts are semantically the same, the following statement can be used to align the classes. Once they have been defined to be equal, members of one class are also members of the second.
sys1:Patient owl:equivalentClass sys2:client.
In addition to
owl:equivalentClass, OWL defines
owl:equivalentProperty to assert that two properties are the same. So far, the discussion of equivalency has only dealt with classes. OWL includes the
owl:sameAs property to assert that individuals are the same.
Sometimes it is also important to assert that two classes or individuals are not the same. For individuals, OWL includes the
owl:differentFrom property. OWL provides a similar concept for classes through the specifying that the classes are disjoint. This means that members of one class cannot be members of the other. OWL provides two different ways to indicate that classes are disjoint;
owl:disjointWith specifies that two classes are disjoint with each other and
owl:AllDisjointClasses which provides a shorthand construct to assert that a set of classes are disjoint with each other.
So far, this post has attempted to introduce some of the main concepts, features and constructs of OWL; however here are many other properties, forms etc that were not discussed. The Resources and Reference section at the end of the post contains links to the full specifications and additional material to aid in getting started with OWL.
OWL Profiles
The various OWL constructs increase the expressiveness of the language but they can also have a cost measured in the computational complexity required to perform such activities as determining class membership. As a result, there is a trade-off between expressiveness and computational complexity. Different uses of OWL might therefore want to select a subset of OWL in order to have better computational characteristics. These limited subsets are referred to as OWL Profiles. The concept of defining targeted subsets of language features as profiles is one that is used in other modeling languages. For example, the Geography Markup Language (GML) defines several profiles including the Point Profile and Simple Features Profile to limit the scope of the language.
OWL 1 defined three profiles, Full, Lite, and DL. The Full profile is the complete OWL specification. All OWL ontologies are valid under the Full profile. The first profile that limited OWL was the Lite profile. Its intent was to define a subset of OWL geared toward easy adoption by tool developers. The profile did not gain much acceptance as a number of tools chose to support other profiles. The final profile defined in OWL 1 is the DL profile, which refers to Description Logic. The intent of the profile was to support a subset of axioms that would ensure that models were decidable. One of the most significant limits the DL profile imposes is that a given resource cannot be treated as a class and an individual. The fact that a model is expressed in a decidable profile does not guarantee good performance.
With OWL 2 three additional profiles were introduced that are further limitation of OWL DL. The first of these is the EL profile which is designed to provide polynomial time determination of a model’s consistency and individual class membership. The EL profile is a good choice for ontologies with large and complex class structures. OWL 2 also defined an RL profile targeted for use with rules processing. The final profile defined by OWL 2 is QL which is a good choice for query processing. It is designed to perform queries in log time based on the number of assertions. One other profile of note is the EL++ profile. This profile is designed to provide polynomial time performance for satisfiability, subsumption, classification, and instance checking reasoning problems. Two of the main limitations of EL++ from OWL DL are prohibition on the use of
owl:allValueFrom and the cardinality restrictions. Again, the Resources and Reference section at the end of the post contains links to information on the specific limitations imposed by each of the profiles.
This post presented a very brief (ok, not that brief as blog posts go) introduction to the Web Ontology Language. The next post wil attempt to tie the series together by presenting an example ontology built to model a problem domain.
Resources and References



{kind=link}